
热点资讯
DeepSeek+华为,能不成超越英伟达和Open AI?
发布日期:2025-02-27 16:29 点击次数:121
中国必须有东说念主宁可选择辛苦又费钱的路套现。
DeepSeek开源动作仍在抓续,激发了AI圈又一轮动荡。
2月21日12点,DeepSeek团队在X平台发布了一段英文执行。浅薄阐述一下,其实说的即是:“从下周开动,我们将开源5个代码仓库,以完全透明的阵势共享我们轻飘但针织的进展。”
紧接着在2月24日,DeepSeek就开源了首个代码库FlashMLA。
用我们得到App AI学习圈支配东说念主快刀青衣老诚的话说,能作念出这样的活动,长短常有派头的。他打了一个比喻:之前开源的是责任后果,就像一个老诚傅,把他总共的教学忘我传授给你。而面前,你不但能拿到老诚傅的隐私,还能看到老诚傅在经过中是如何干活儿的。这对好多东说念主来说,会比驱散更有价值。
虽然,列国网友对DeepSeek这一动作都不乏赞好意思之辞,反响十分热烈。
今天我们先不细究代码库FlashMLA的责任道理,而是想来聊一下,从DeepSeek R1发布以来许多东说念主在念念考的一个问题:着实具有“开源精神”的DeepSeek加上华为,能不成超越英伟达和Open AI?
偶合前不久,我们得到的万维钢老诚,在他的专栏里花大篇幅修起了这个问题。本文选自《万维钢·精英日课6》,文中万老诚用更全面、更永恒的视角,探讨了为什么AI需要越来越强的算力,以及中国为什么要恣意芯片本领收尾、坚抓恒久参加通用东说念主工智能研发等问题。
底下,请万维钢老诚为你共享:
来源:《万维钢·精英日课6》
01
对算力的需求永无至极
DeepSeek选择了一些玄妙的优化状貌,莽撞用相比少的算力已矣o1级别的功能,这相配了不得,这对中国——也对好意思国——的大模子研发者都是天大的好音问。
但这毫不是说以后英伟达那种高等芯片就没用了,咱国产芯片就够用了。面前AI缩放定律远远莫得看到尽头,更高的智能条件更高的算力这个根柢原则并莫得变。
要知说念就算莫得DeepSeek,别家公司和科研团队,包括OpenAI我方,也在优化模子性能,再磋商到英伟达芯片升级,用山姆·奥特曼的话说即是“模子输出老本每年都会缩小十倍”(即降至本来的十分之一)。
假定DeepSeek恣意之前那一刻,OpenAI用100的算力得到100的智能,DeepSeek恣意了,群众用10的算力就能得到100的智能——但你的方针不是100的智能,而是一万、致使一百万的智能,是以你仍然需要比面前越过百倍千倍的算力。
是以对算力的需求面前来说照旧无至极的。
但英伟达并非安枕而卧,好意思国有好几家公司在作念我方的AI芯片,中国也有包括华为、寒武纪、百度、壁仞科技等等正在追逐。那么国产AI芯片的水平相关于英伟达来说到底如何呢?国产最强的是华为昇腾。
我让ChatGPT Deep Research调研何况制作了底下这张表格,把华为昇腾和英伟达近几年的主流GPU作念了个对比——
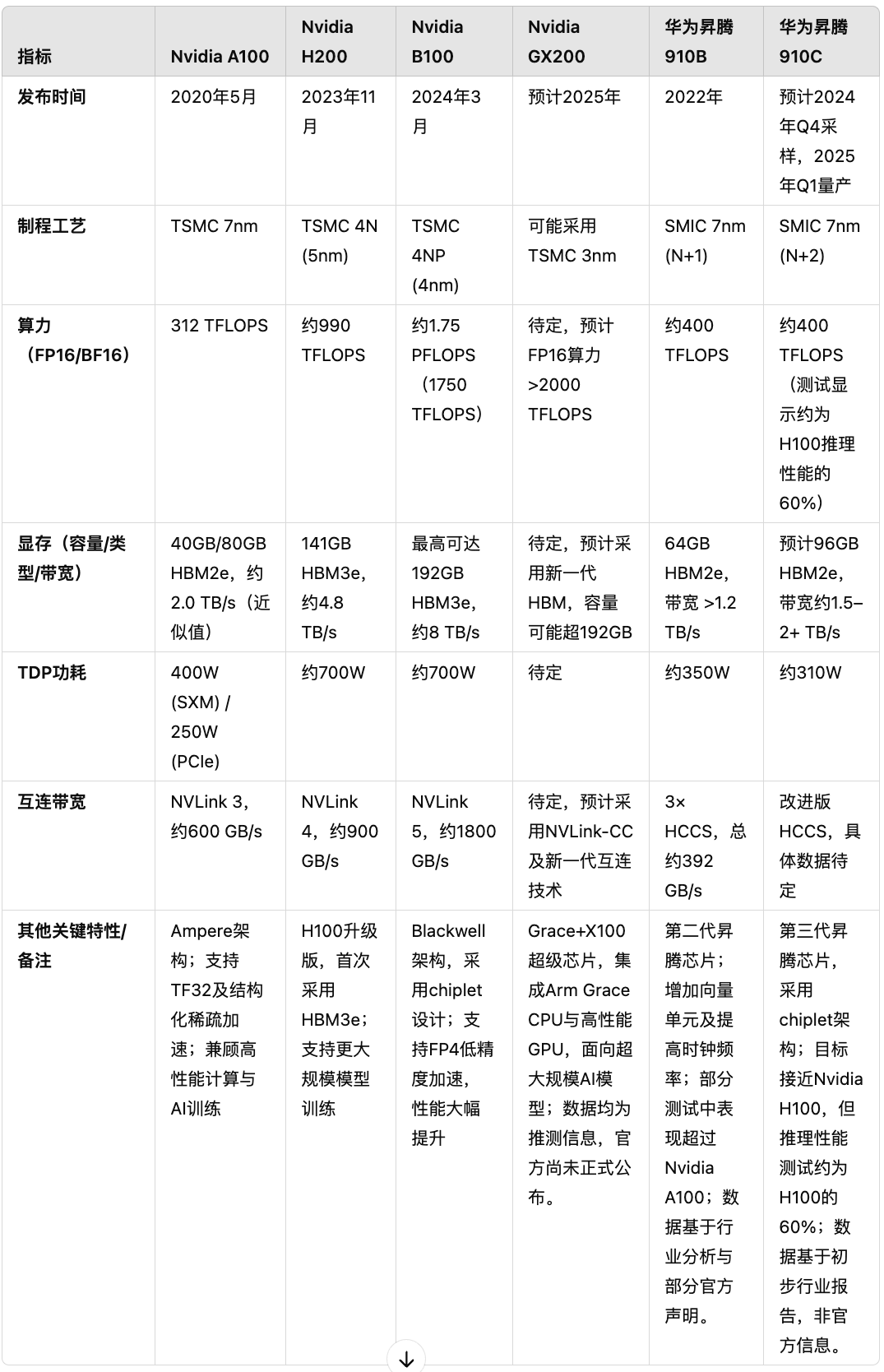
这个驱散不错说是既不让东说念主悲不雅,又不让东说念主乐不雅。现时能用的最强国产GPU是2022年发布的华为昇腾910B,它的性能在某种道理上依然略略卓著面前仍然被好多AI公司芜俚使用的、英伟达2020年发布的A100。这很进犯,这确认就算好意思国对中国搞全面断供,中国也能络续历练AI。
但910B比英伟达面前确住持芯片,2023年发布的H200和24年发布的B100,就差距相比大了,算力苟简极端于英伟达的二分之一到四分之一。华为2025年行将量产昇腾910C,基础算力与910B差未几,推感性能外传达到英伟达之前H100的60%。但英伟达2025年会推出GX200,算力预估是910C的五倍。
02
高等智能一定是通用智能
为什么英伟达在络续突飞大进,而华为有点接近极限的道理?
这里最进犯的原因即是光刻制程。
英伟达A100和华为昇腾系列都是7纳米制程,在这个步调上中芯外洋能作念。只是在910C这个级别条件N+2制程,中芯外洋的良率外传很低,这意味着出产老本高。而英伟达H系列、B系列、GX系列分手是5纳米、4纳米、3纳米制程,中芯外洋作念不了。
因为中国大陆莫得极紫外光刻机。《精英日课》讲《芯片战役》一书的时候说过,极紫外光刻机极其不可能靠一个国度完全自强门庭造出来,面前看至少将来十年之内可能性不大。
是以现时最可行的目的,照旧从英伟达买。
那你说面前DeepSeek依然很好用,我们就在这个基础上进步性能行不行,何苦非得追求最高的性能呢?我合计那是万万不行的。
要知说念DeepSeek是个相对相比小的模子,它是不错跟o1对标,但o1也不是超大模子。
就在2025年下半年,也许更早,OpenAI会推出GPT-5,那将是一个超大的模子。它会像面前GPT-4o一样领有端对端历练出来的多模态,它将不但能阅读图像,而且能阅读视频和音频,它将能处理海量的数据——是以它需要好多张GPU。DeepSeek不会消释这种模子。
再者,更进犯的是,炒股配资AGI、以及紧接着更进犯的ASI,即是需要超大的算力—— 因为高等智能一定是通用智能。
DeepSeek R1的效力高,有好多草创性的本领,关联词我们也不成否定,其中有一定以糟跶宽度调换效力的因素。
R1和之前的V3都是「羼杂群众(mixed experts)」模式,是可能最早法国的Mistral模子先选择的,是把智能散播开成些许个群众模块,每次遭遇新任务就只调用相关的模块,而无谓「全脑」一都念念考,这就大大省俭了算力。
这个作念法极端于你问我数学题我就用数学模块,问我古诗词我就用古诗词模块。但我们瞎想,关于更复杂的问题,也许即是需要同期调用几个领域的学问和念念维模式本领责罚。
极端是创造力老是来自不同倡导的集会,那么这个模块分割法就会收尾领略。再者,DeepSeek专注于数学、编程息兵话处理这几个领域,亦然为了省俭算力不得不为之。
就在最近,斯坦福大学李飞飞的团队发明了一个更激进的作念法,堪称只用不到50好意思元(有个说法是6好意思元)的历练用度就弄出一个数学解题水平跟R1、o1差未几的推理模子,叫S1。他们是如何作念的呢?
第一,从开源的通义千问(qwen)的一个小版块谈话模子开动,省去前期大界限的历练;
第二,用一千说念精选数学题挑升历练数学解题才略,且只历练数学才略;
第三,用Google Gemini的一个推理版块的推理经过的蒸馏数据来历练我方的推理才略。
这个作念法,就如同找个脑子快的孩子,给他一套精选习题集,让他背诵别东说念主的解题套路。这样历练作念题家虽然快,关联词这除了快莫得别的孝敬。这个作念法不会像R1那样涌现出任何新才略,不会给你任何惊喜。
这不是通往AGI之路。
03
更多的参数+更长的念念考时间=更好的谜底
梁文锋胸怀大志,竣工不单是想提供一个低廉的作念题家,而是想作念AGI。接下来的情形,我推测,差未几是底下这样的——
关于一般的日常任务,比如一般编程、搞个会议纪要、写个讲述责任的发言稿、弄个报表之类,独一用泛泛模子就不错,中国不但没问题而且可能有价钱和服务上的上风,也许中国的模子是最佳的。
但关于科研任务,极端是探索最前沿恣意,你需要能想得很广而且很深,你需要尽可能地堆积算力。我有个说法是淌若一个科研团队赋闲花5000好意思元问ChatGPT一个问题,而另一个不异水平的科研团队赋闲花一万好意思元,那么后者将得到更好的谜底——只是是因为模子赋闲为他们念念考更永劫期。
独一缩放定律仍然有用,那么,更多的参数+更长的念念考时间=更好的谜底
亦然更值钱的谜底。接下来AI在科研领域会技艺额外,科研发现的速率会加速,是以争夺会相配热烈。一种新药只可被发现一次,谁先作念出来即是谁的。
还有一个在我看来最进犯的磋商,是谁先达到ASI。
我们这里不妨界说ASI是「我方不错历练我方」的超等东说念主工智能。那么谁先达到ASI,谁就等于是取得了一个竣工的最初上风。这就极端于计谋游戏里谁先造出「奇不雅」来,能大大加强我方的计谋上风。
试想淌若好意思国率先达到ASI,那就意味着以后的路全买通了,剩下的事只是给AI喂芯片喂电力良友,不需要东说念主类科学家再有奇念念妙想,可谓是安枕而卧——那到时候中国如何办呢?还靠一帮东说念主极力追逐吗?
走时的是中国有个DeepSeek。就在DeepSeek的论文中,依然表深远小数迹象,模子我方给我方提议了一个算力优化策略。你不错说梁文锋依然看到了ASI的光芒。我们瞎想OpenAI详情也有肖似的东西,但他们从未公开过。
DeepSeek震撼好意思国这段时间,Anthropic CEO达里奥·阿莫迪(Dario Amodei)有一些公开言论,很耐东说念主寻味。他说淌若不收尾中国发展AI,那会对全东说念主类都有平正,我们会迎来突飞大进的十年——关联词中国会把AI用于军事,而这对好意思国很不利,是以他号令好意思国政府加强对中国AI的收尾。他还说,真但愿DeepSeek团队到好意思国来为他们公司责任。
这些言论在X上遭到了好意思国网友的围攻。起首你动作一个科技公司CEO去强调地缘政事,这本人即是错的:科技应该为全东说念主类服务。再者你咋这样会想呢?东说念主家DeepSeek凭啥到好意思国来帮你干?
这些言论进一步确认了DeepSeek的计谋道理。接下来好意思国政府有可能加强对中国AI的收尾,致使完全脱钩,但也有可能松动英伟达的出口料理,毕竟跟特朗普什么都不错谈。无论如何,我们必须认准ASI这个大地点,而竣工不成得志于解解数学题、日常编程那些任务。
总想四两拨千斤、少用钱多工作儿、以20%的参加责罚80%的问题,那是走不远的。
中国必须有东说念主宁可选择辛苦又费钱的路。